Peeking under the hood of competitors’ sites is super easy with the Chrome UX Report API. It gives you access to site speed data for millions of websites that real users experienced.
All you have to do is plug this cURL into the command line:
API_KEY="[YOUR_API_KEY]"
curl "https://chromeuxreport.googleapis.com/v1/records:queryRecord?key=$API_KEY" \
--header 'Content-Type: application/json' \
--data '{"origin": "https://web.dev"}'That will give you a JSON response where you can pick out the 75th percentile numbers for the Core Web Vitals and First Contentful Paint.
...
"first_contentful_paint": {
"histogram": [
{
"start": 0,
"end": 1800,
"density": 0.87723861930965186
},
{
"start": 1800,
"end": 3000,
"density": 0.082941470735367437
},
{
"start": 3000,
"density": 0.039819909954977431
}
],
"percentiles": {
"p75": 1236
}
}
...That is perfectly fine for getting the Vitals for one origin. But what about multiple origins?
Batch querying origin data using Python
Requesting CrUX data for multiple origins is a breeze in Python:
#!/usr/bin/env python3
import requests
from datetime import datetime
import csv
import re
# Sorry to rag on you news sites again for perf examples!
# Enter the URLS of the origins you want to get the Web Vitals for here:
urls = [
"https://news.yahoo.com/",
"https://news.google.com/",
"https://www.huffpost.com/",
"https://edition.cnn.com/",
"https://www.nytimes.com/",
"https://www.foxnews.com/",
"https://www.nbcnews.com/",
"https://www.dailymail.co.uk/",
"https://www.washingtonpost.com/",
"https://www.theguardian.com/",
]
# Add your API key here.
# You can get one at https://developers.google.com/web/tools/chrome-user-experience-report/api/guides/getting-started#APIKey
API_KEY = "[YOUR_API_KEY]"
def strip_URL(str):
url = str
url = re.sub(r'^(https:\/\/)(www.)?', '', url)
url = re.sub(r'\/.*', '', url)
return url
date = datetime.now()
output = []
for url in urls:
headers = {"Content-Type": "application/json"}
# If you want to get the CrUX data just for phones,
# set the POST request data to '{"origin": url, "formFactor": "PHONE"}'
data = {"origin": url}
# Make sure to send the JSON data using a POST request.
# Serialize the JSON data using 'json' parameter.
# Using 'data' will give you errors.
response = requests.post(
f"https://chromeuxreport.googleapis.com/v1/records:queryRecord?key={API_KEY}", headers=headers, json=data)
if response.status_code == 200:
stripped_URL = strip_URL(url)
print(f"Getting CrUX data for {stripped_URL}")
response_JSON = response.json()['record']['metrics']
try:
p75_fcp = response_JSON['first_contentful_paint']['percentiles']['p75']
p75_lcp = response_JSON['largest_contentful_paint']['percentiles']['p75']
p75_fid = response_JSON['first_input_delay']['percentiles']['p75']
p75_cls = response_JSON['cumulative_layout_shift']['percentiles']['p75']
output.append([url, stripped_URL, p75_fcp,
p75_lcp, p75_fid, p75_cls])
except KeyError:
print(
f'Skipping {url}. Data in the response seems to be missing.')
elif response.status_code == 404:
print(f'Not enough speed data for {url}')
else:
print("Request error:")
print(response.status_code)
output.insert(0, ['test_url', 'origin', 'p75_fcp',
'p75_lcp', 'p75_fid', 'p75_cls'])
# Export to CSV
csv_filename = f'{str(date)}.csv'
with open(csv_filename, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(output)
print('Updated CSV')Then you can just open up the resulting CSV in your spreadsheet editor of choice and visualize the data with a couple of clicks.
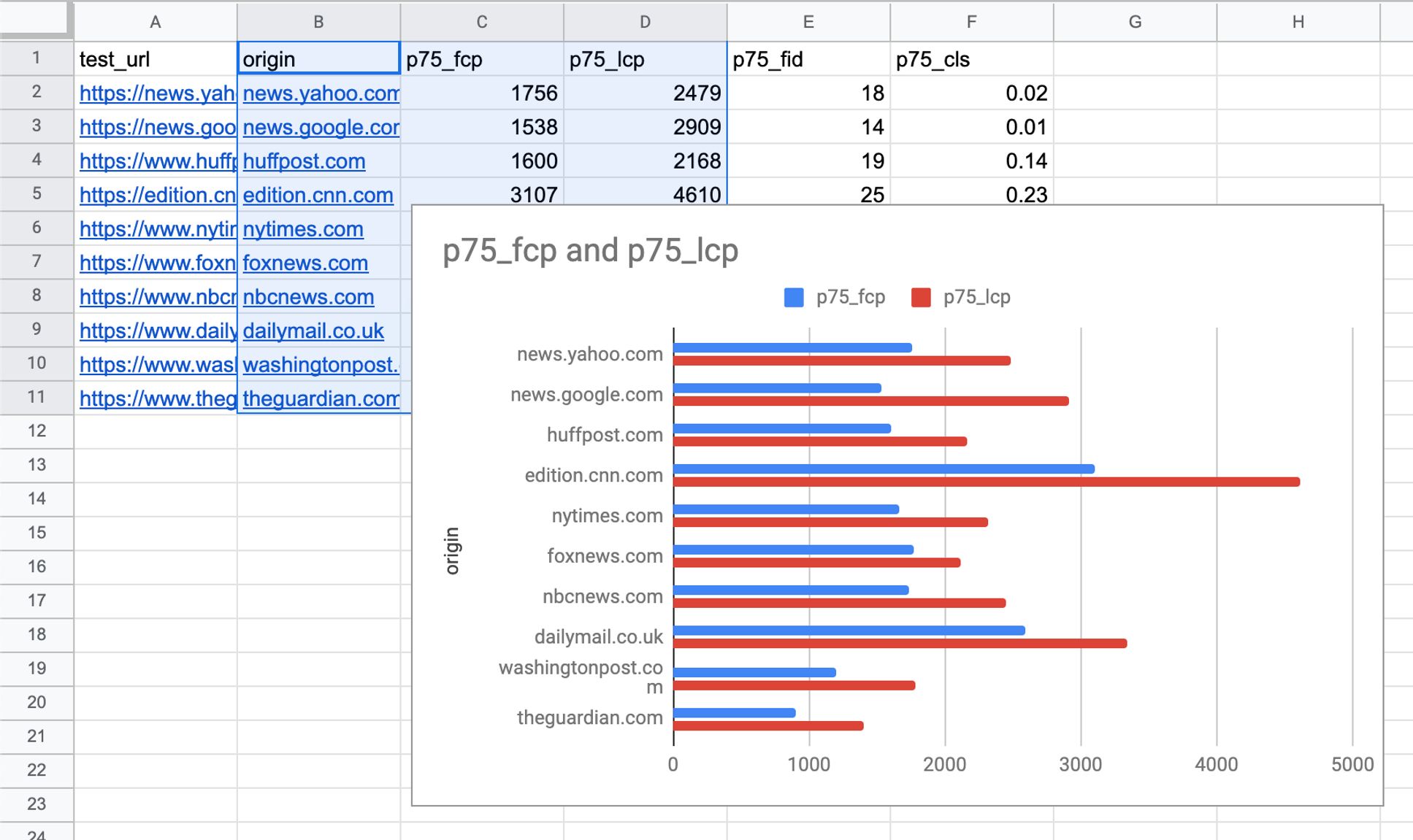
Get CrUX data for multiple URLs
Sending a POST request to the CrUX API using origin in the data parameter will of course give you data for the origin, no matter what URL you put in.
# If 'url' is 'https://www.nytimes.com/section/science' and you request 'origin' data,
# you'll get it for 'https://www.nytimes.com'.
data = {"origin": url}But if you want to get CrUX data for multiple page URLs, simply change the POST data parameter to url:
# If 'url' is 'https://www.nytimes.com/section/science' and you request 'url' data,
# you'll get it for 'https://www.nytimes.com/section/science'.
data = {"url": url}Be aware that CrUX may not have enough site speed data for a specific URL. The Python script will handle errors accordingly.
Putting things into perspective
Using CrUX data alone doesn’t provide a complete picture of site speed as it is only based on Chrome user data (i.e. the Chrome users that share their usage statistics with Google). So if you need to understand competitor sites’ performance in Safari or Firefox, you’ll have to use other tools.
But since Chrome has a big share of the browser market and the CrUX API so accessible (the API explorer is free to use), you can at least understand how Google sees your site’s and competitors’ sites performance.